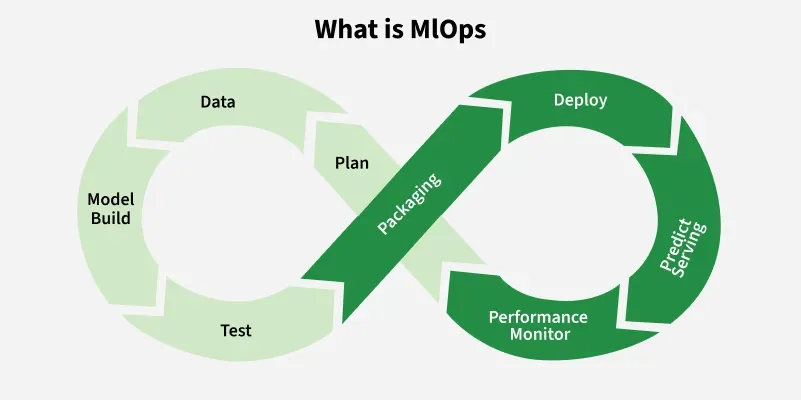
What is MLOps?
MLOps (Machine Learning Operations) is a set of practices that combines machine learning, DevOps, and data engineering to streamline the development, deployment, and maintenance of machine learning systems in production.
Think of it as applying software engineering best practices to machine learning workflows—but with additional complexity due to data, model versioning, and continuous retraining requirements.
The MLOps Landscape
Core Pillars
┌─────────────────────────────────────────┐
│ ML Model Development │
│ (Experimentation, Training, Tuning) │
└────────────────┬────────────────────────┘
│
┌────────────────┴────────────────────────┐
│ Model Validation & Testing │
│ (Metrics, A/B Testing, Performance) │
└────────────────┬────────────────────────┘
│
┌────────────────┴────────────────────────┐
│ Model Deployment & Serving │
│ (Containerization, APIs, Scaling) │
└────────────────┬────────────────────────┘
│
┌────────────────┴────────────────────────┐
│ Monitoring, Retraining & Governance │
│ (Data Drift, Performance, Compliance) │
└─────────────────────────────────────────┘
Key Components
1. Data Management
- Data Pipeline: Automated extraction, transformation, and loading (ETL)
- Data Versioning: Track datasets like code (DVC, Delta Lake)
- Data Quality: Validation, schema enforcement, anomaly detection
- Feature Store: Centralized feature management and serving
2. Model Development
- Experimentation Tracking: Log hyperparameters, metrics, artifacts (MLflow, Weights & Biases)
- Model Registry: Version control for trained models
- Reproducibility: Environment specifications, random seeds, documentation
- Collaboration: Shared resources for data scientists and engineers
3. Model Validation
- Unit Testing: Data and model logic validation
- Integration Testing: End-to-end pipeline testing
- Model Evaluation: Performance metrics on holdout sets
- A/B Testing: Compare models in production with real user traffic
- Fairness & Bias Detection: Ensure model equity across demographics
4. Deployment & Serving
- Containerization: Docker for reproducible environments
- Orchestration: Kubernetes for managing deployments at scale
- Model Serving: REST APIs, gRPC, batch inference, real-time serving
- Version Management: Blue-green deployments, canary releases, rollback capabilities
5. Monitoring & Governance
- Performance Monitoring: Track model predictions, latency, throughput
- Data Drift Detection: Alert when input distributions change
- Model Decay: Monitor accuracy degradation over time
- Audit Trails: Compliance logging for regulated industries
- Cost Optimization: Track infrastructure and compute costs
MLOps Workflow
From Experimentation to Production
Notebook Experimentation
↓
Feature Engineering & Versioning
↓
Model Training Pipeline (Automated)
↓
Model Validation & Testing
↓
Model Registry & Packaging
↓
Containerization & Artifact Storage
↓
Deployment to Staging Environment
↓
A/B Testing & Validation
↓
Production Deployment
↓
Monitoring & Alerting
↓
Retraining Triggers (Data/Model Drift)
↓
Loop Back to Training
Popular MLOps Tools
Experiment Tracking & Model Management
- MLflow: Open-source platform for managing ML lifecycle
- Weights & Biases: Cloud-based experiment tracking and hyperparameter optimization
- Neptune.ai: Lightweight experiment tracking for teams
Data Management
- DVC (Data Version Control): Version control for data and pipelines
- Apache Airflow: Workflow orchestration and DAG scheduling
- Prefect: Modern data orchestration platform
- Delta Lake: ACID transactions for data lakes
Model Serving
- TensorFlow Serving: Specialized serving for TensorFlow models
- Seldon Core: Open-source model serving platform on Kubernetes
- BentoML: Framework for packaging and deploying ML models
- Ray Serve: Distributed model serving framework
Monitoring & Observability
- Datadog: Infrastructure and APM monitoring
- Prometheus + Grafana: Metrics collection and visualization
- WhyLabs: ML model monitoring and data quality
- Arize: ML model monitoring and explainability
Infrastructure & Operations
- Kubernetes: Container orchestration
- Docker: Containerization
- Terraform: Infrastructure as Code
- Jenkins / GitLab CI / GitHub Actions: CI/CD pipelines
MLOps Best Practices
Development
-
Treat data like code
- Version datasets and transformations
- Automate data pipeline testing
- Document data lineage
-
Reproducibility First
- Lock dependencies (requirements.txt, environment.yml)
- Document model training steps
- Store random seeds and hyperparameters
-
Modular Design
- Separate feature engineering from model training
- Use configuration files (YAML, JSON) for hyperparameters
- Build reusable components
Testing
-
Comprehensive Testing Strategy
- Unit tests for data transformations
- Integration tests for full pipelines
- Model performance tests against baselines
- Test edge cases and adversarial inputs
-
Automated Validation
- Schema validation for inputs and outputs
- Range checks for features
- Bias and fairness audits
Deployment
-
Infrastructure as Code
- Define environments declaratively
- Version control infrastructure changes
- Automate provisioning
-
Progressive Rollouts
- Start with canary deployments (1-5% traffic)
- Monitor metrics closely during rollout
- Have automated rollback mechanisms
Monitoring
-
Observability
- Log predictions and features
- Monitor model accuracy in real time
- Track data distributions for drift detection
- Set up alerts for anomalies
-
Feedback Loops
- Capture true labels as they become available
- Use actuals to retrain models
- Monitor feedback quality
Organization
-
Clear Ownership
- Define roles: data engineer, ML engineer, ML ops engineer
- Establish SLOs (Service Level Objectives) for models
- Document runbooks for common issues
-
Governance & Compliance
- Audit trail for model decisions
- Explainability/interpretability requirements
- Data privacy and regulatory compliance
Real-World Challenges
Technical Challenges
- Data Quality: Garbage in, garbage out
- Model Complexity: Balancing accuracy vs. interpretability vs. latency
- Scalability: Handling millions of predictions per second
- Reproducibility: ML experiments are inherently non-deterministic
Organizational Challenges
- Silos: Data science isolated from engineering
- Skills Gap: Few engineers understand both ML and infrastructure
- Time to Market: Experimentation cycles are long
- Cost Control: Compute resources can quickly become expensive
Getting Started with MLOps
Level 1: Manual Processes
- Jupyter notebooks for experimentation
- Manual model files and version tracking
- Basic monitoring with logs
Level 2: Automated Pipelines
- Automated training pipelines with cron jobs
- Version control for code and models
- Basic monitoring dashboards
Level 3: Continuous Integration
- Automated testing on code changes
- CI/CD pipelines for model training and deployment
- Experiment tracking and model registries
Level 4: Full MLOps Maturity
- End-to-end automation and orchestration
- Advanced monitoring with drift detection
- Automated retraining triggers
- Multi-model experimentation and A/B testing
- Governance and audit trails
Conclusion
MLOps is essential for scaling machine learning from experimentation to reliable, production systems. It bridges the gap between data science innovation and operational stability.
Key Takeaways:
- MLOps combines ML, DevOps, and data engineering practices
- Success requires automation at every stage
- Monitoring and feedback loops are critical
- Start simple and mature gradually
- Team collaboration and clear processes matter as much as tools
The goal isn’t perfect tooling—it’s sustainable, scalable ML systems that deliver business value.